Project Overview
The **Medical Chatbot for Prescription-Based Query Assistance** is a sophisticated AI-driven application meticulously engineered to enhance access to, and comprehension of, complex medical information, with a pronounced focus on prescription data. In an age where individuals are often inundated with medical jargon and intricate healthcare directives, this project stands as a beacon of clarity. It leverages state-of-the-art Natural Language Processing (NLP), Optical Character Recognition (OCR), and Large Language Model (LLM) technologies to distill convoluted medical documents into clear, concise, and actionable insights.
The Project's Core Concept.
The fundamental problem this project addresses is the pervasive difficulty patients encounter when trying to understand medication names, dosages, complex administration schedules, potential side effects, and drug interactions as detailed on prescriptions or in medical reports. This lack of clarity can lead to medication errors, poor adherence, and increased anxiety. By automating the extraction, interpretation, and contextual explanation of this information, the chatbot functions as an intelligent, empathetic assistant. It empowers patients to take a more active and informed role in managing their health and medication regimens, fostering a greater sense of control and confidence. The system's vision extends to democratizing medical knowledge, making it more accessible and less intimidating for the average user.
Beyond prescriptions, the system is architected to process a variety of medical documents (e.g., lab reports, discharge summaries if provided by the user) and offer general health-related guidance based on user queries and self-reported symptoms. It aims to bridge the communication gap between healthcare providers and patients by offering a supplementary tool for information reinforcement and clarification. The ultimate goal is to contribute to improved health literacy, better patient outcomes, and a more collaborative healthcare experience.
The target audience is diverse:
- Patients and Caregivers: Seeking to demystify their prescriptions, understand medical conditions, track health parameters, and manage appointments more effectively.
- Healthcare Providers: Potentially using it as a supplementary tool to reinforce patient education, answer common patient questions, and free up time for more complex clinical decision-making (though this project is not a diagnostic tool).
- Developers and Researchers: Interested in exploring and contributing to applications at the intersection of AI, NLP, and healthcare, using the project as a foundational platform.
The project's modular architecture, reliance on well-established open-source technologies, and focus on user-centric design make it a robust foundation for future innovation, scalability, and potential integration into broader digital health ecosystems.
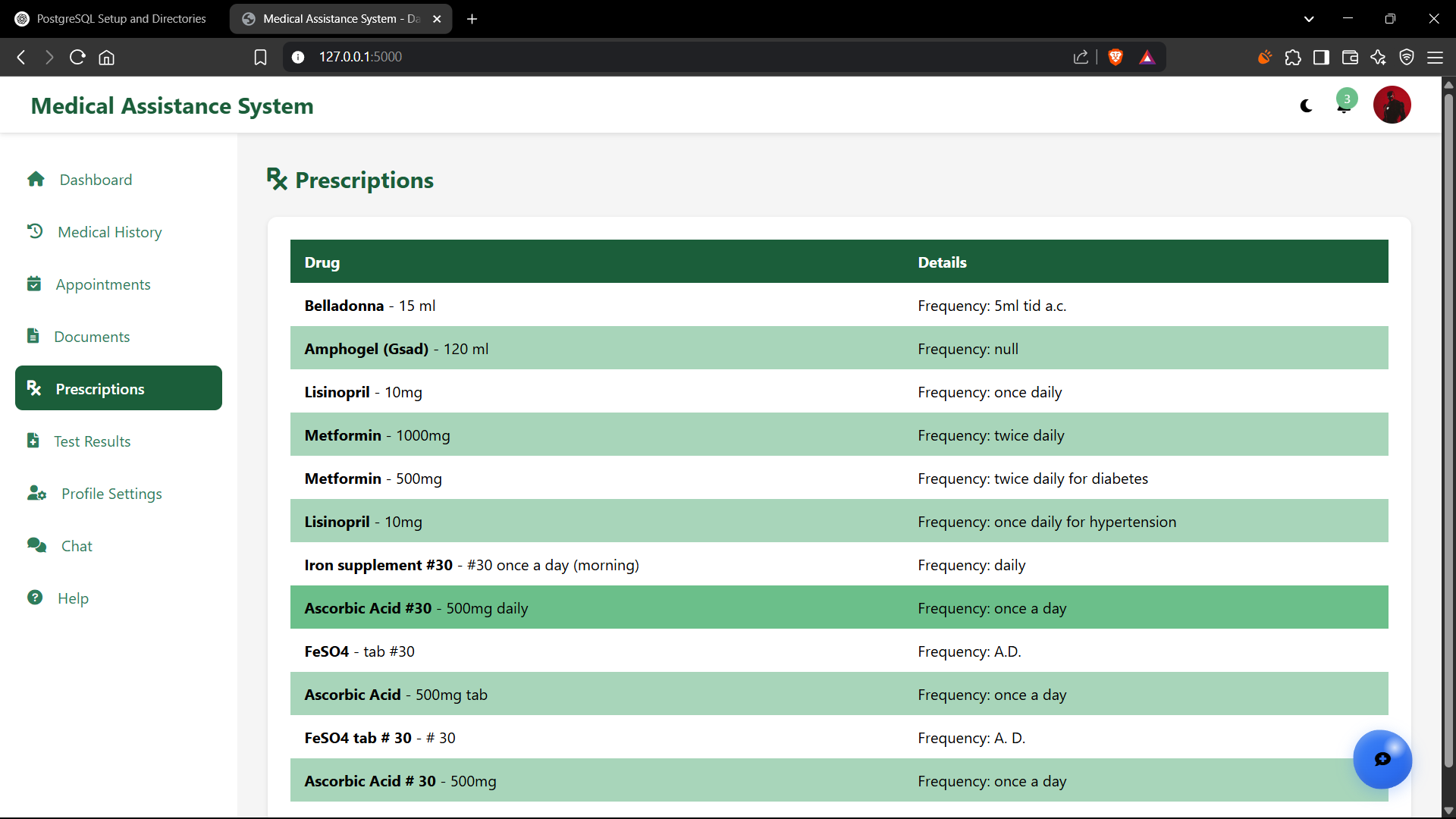
Key Features
The chatbot is endowed with a comprehensive suite of features, each meticulously designed to provide holistic and user-centric medical information assistance:
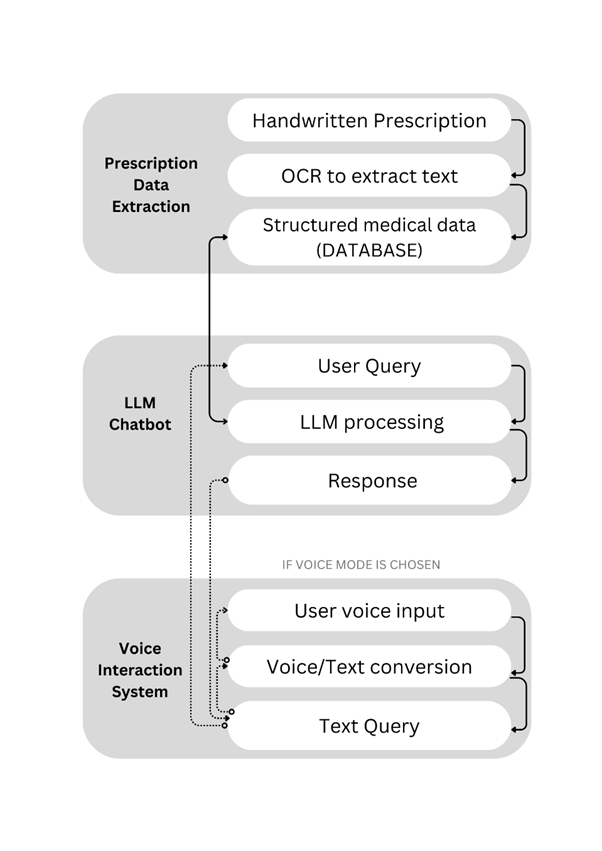
Illustrating a Key Feature of the Chatbot.
Due to Computing Contraints, instead of local vision language model, gemini api is being used
Leverages the formidable Google Gemini API, renowned for its advanced multimodal understanding including OCR, to accurately and reliably extract structured data from diverse prescription formats. This includes deciphering both printed text and, critically, challenging handwritten prescriptions which are notorious for their variability. Key extracted elements include medication names (brand and generic), dosages, administration frequencies (e.g., "take one tablet twice daily"), routes of administration (e.g., oral, topical), and prescribed duration. The accuracy here is paramount as it forms the basis for many subsequent features.
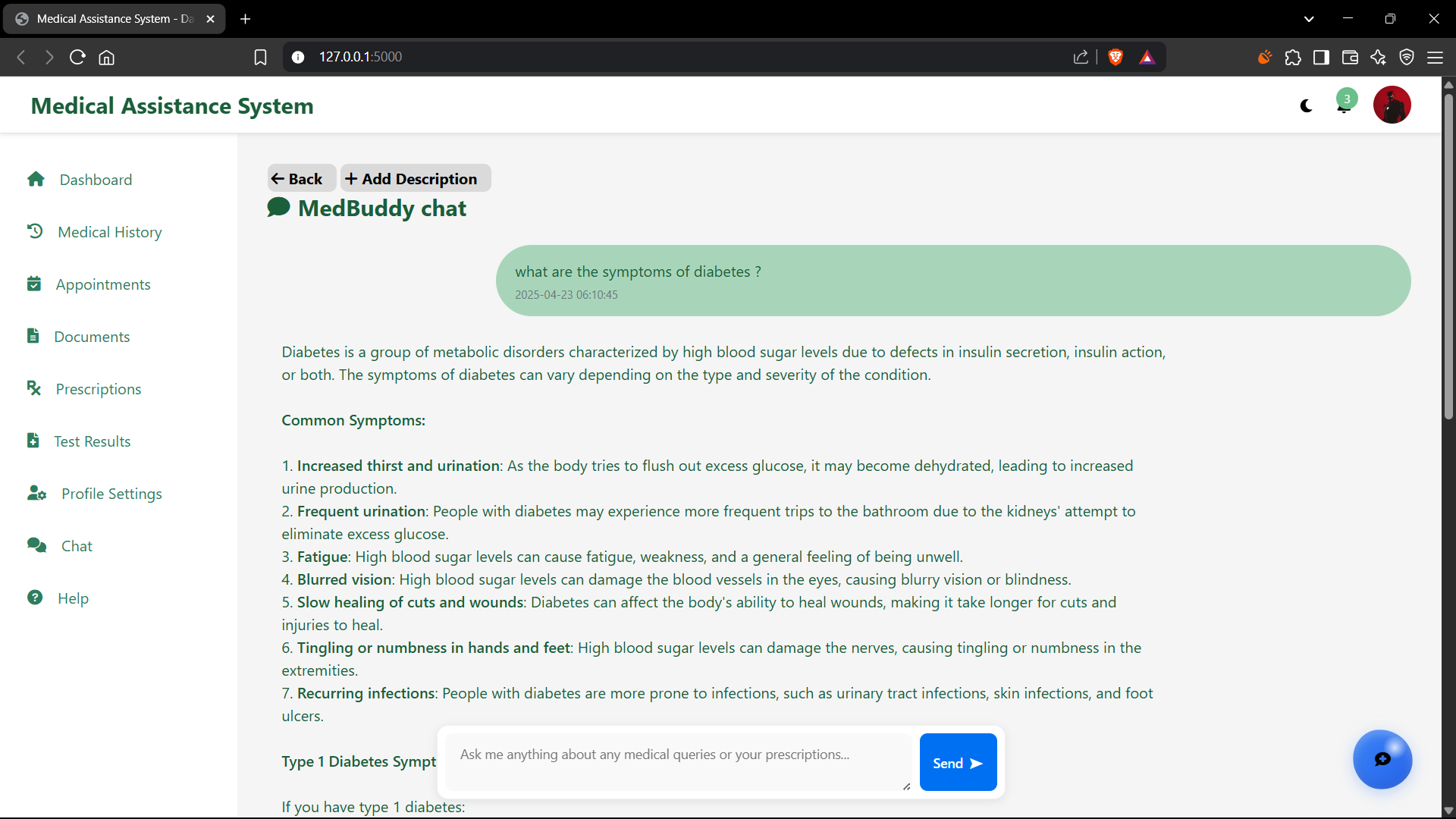
Utilizes the Meta Llama 3.2 8B Instruct model, a powerful yet relatively lightweight LLM, augmented with a sophisticated Retrieval-Augmented Generation (RAG) mechanism. When a user describes symptoms, the RAG system first retrieves relevant, vetted information from its knowledge base (which can include user-uploaded documents or curated medical texts). This retrieved context is then provided to Llama 3.2 to generate an informed response. This approach mitigates LLM "hallucinations" and grounds responses in factual data. The system can offer general information about conditions, explain potential (not definitive) causes, or, crucially, recommend when to seek professional medical advice, always emphasizing it is not a diagnostic tool.
Employs a custom-built lexicon and NLP techniques to intelligently identify and expand common, often cryptic, medical abbreviations (e.g., "q.i.d." to "four times a day," "PRN" to "as needed," "PO" to "by mouth"). This significantly enhances clarity and understanding for users unfamiliar with medical shorthand, making prescriptions and medical notes far more accessible.
Maintains a secure and persistent history of user interactions and chat sessions within the robust PostgreSQL database. This allows the chatbot to provide personalized and context-aware responses, remembering previous queries, uploaded document contents, and user preferences across conversations. For example, if a user previously uploaded a prescription for "Metformin," they can later ask "What are the side effects of my medication?" without re-specifying it. This feature is key to a more natural and efficient user experience.
Offers a user-friendly interface and corresponding API endpoints for robust chat session management. Users can easily create new, distinct chat sessions (e.g., one for a specific prescription, another for general health queries), retrieve and review past conversations, and securely delete sessions if they wish, giving them full control and privacy over their interaction data.
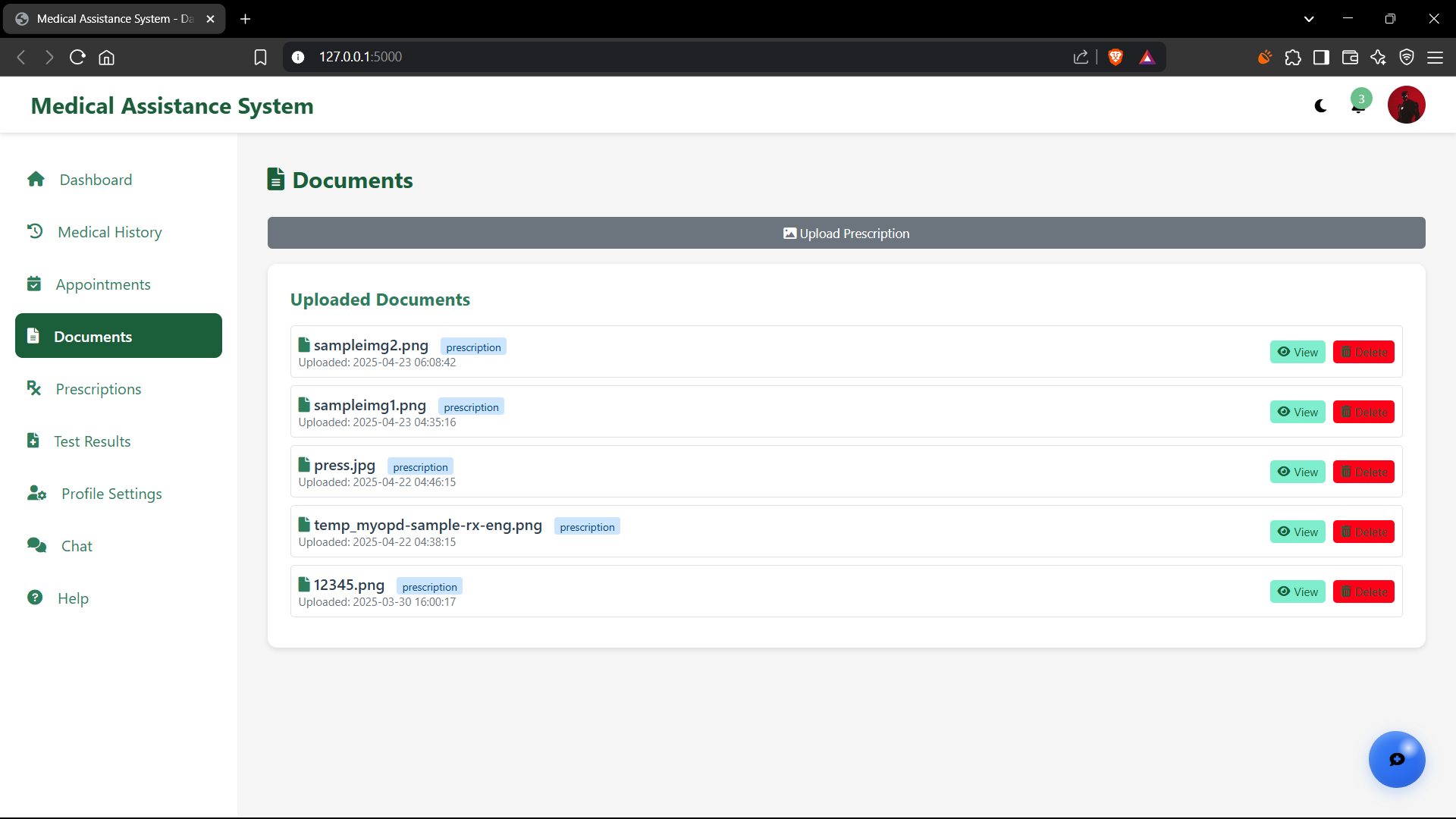
Facilitates secure user uploads of various document types, including text files (.txt, .md) and images (.png, .jpg, .jpeg) of medical documents. The system processes these documents: images undergo OCR via Gemini, and text is parsed using NLP techniques. The extracted content is then chunked, embedded using sentence-transformer models, and indexed into the Chroma DB vector store. This enables the RAG system to perform semantic searches, retrieving highly relevant information from the user's own documents to answer their specific questions.
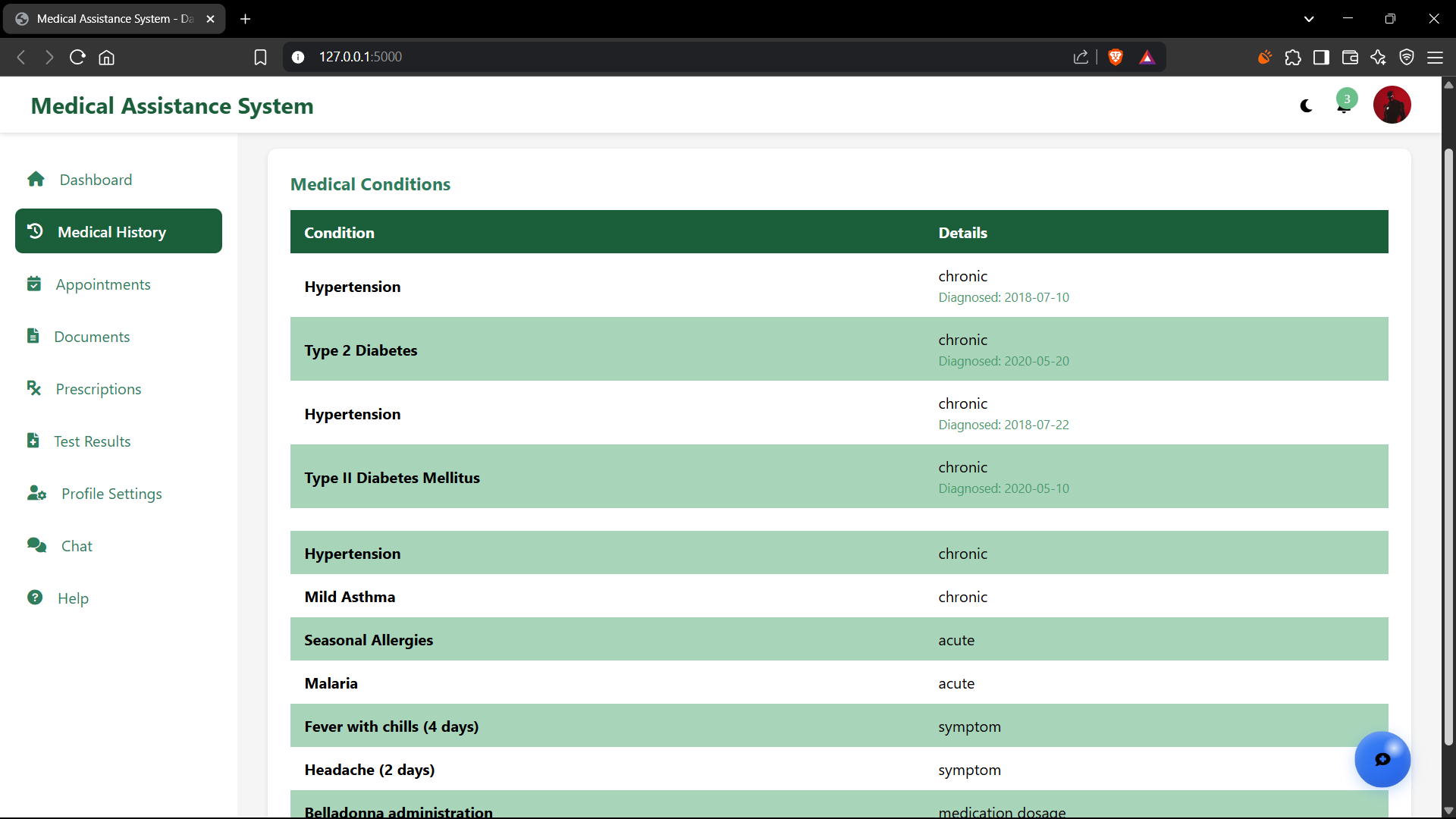
Provides an interface for users to manually input and track key vital signs such as body temperature, heart rate, blood pressure (systolic/diastolic), and respiratory rate. This data is stored historically, allowing users to monitor trends. Future enhancements could involve using this data to provide more personalized (non-diagnostic) health insights or flag significant deviations that might warrant medical attention.
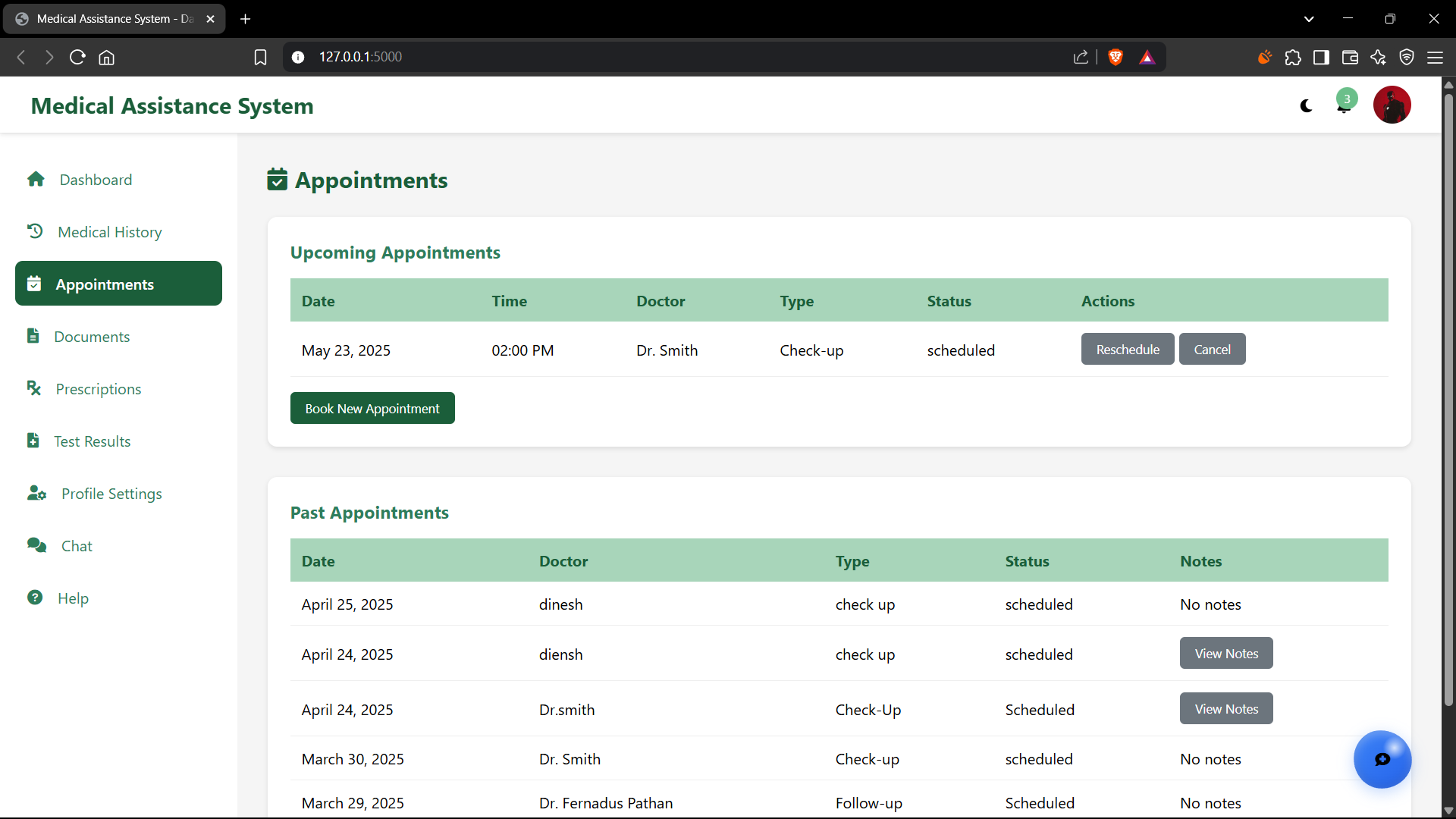
Includes functionalities to create, retrieve, update, and categorize medical appointments. Users can input appointment details (doctor, specialty, date/time, location, notes) and receive reminders (a potential future extension). This feature aims to consolidate health-related information management within a single, accessible platform, helping users stay organized with their healthcare schedule.
Integrates OpenAI's Whisper model for highly accurate speech-to-text (STT) conversion, allowing users to interact with the chatbot using natural voice commands, enhancing accessibility and convenience. Complementary text-to-speech (TTS) capabilities (using libraries like `gTTS` or browser-native APIs) provide auditory responses, making the system more accessible for users with visual impairments or those who prefer auditory information.
Technology Stack
The project's architecture is founded upon a carefully curated stack of modern, powerful, and predominantly open-source technologies, selected for their robustness, scalability, and suitability for AI-driven healthcare applications:
Diagram of the Technology Stack.
-
Language Models:
- Meta Llama 3.2 8B Instruct: This state-of-the-art Large Language Model (LLM) serves as the core conversational intelligence. Chosen for its strong reasoning and instruction-following capabilities relative to its size, making it deployable locally (e.g., via Ollama) with reasonable hardware (GPU highly recommended). It's used for generating human-like text, summarizing information, and understanding nuanced queries, especially when augmented by RAG.
- Sentence-Transformers (e.g., `all-MiniLM-L6-v2`): These models are crucial for the RAG system. They convert text chunks (from documents or queries) into dense vector embeddings, capturing semantic meaning. `all-MiniLM-L6-v2` is chosen for its excellent balance of performance and speed, suitable for generating embeddings quickly.
-
Backend Framework:
- Flask: A Python microframework. Its lightweight nature, flexibility, and extensive ecosystem make it ideal for building the backend API. Flask allows for rapid development and easy integration with other Python libraries. It handles HTTP requests, defines API routes (e.g., for chat, document upload, user authentication), and orchestrates the application's logic.
-
Database & ORM:
- PostgreSQL: A highly reliable, feature-rich open-source relational database. Chosen for its robustness, support for complex queries (e.g., JSONB for flexible data storage), ACID compliance (essential for data integrity), and scalability. It stores user data, chat histories, document metadata, vital signs, and appointment information.
- SQLAlchemy: A comprehensive Python SQL toolkit and Object-Relational Mapper (ORM). It provides a high-level, object-oriented interface to interact with PostgreSQL, abstracting raw SQL. This simplifies database operations, improves code readability, and makes schema management easier (e.g., with Alembic for migrations, if integrated).
-
NLP & AI Orchestration Libraries:
- LangChain: A powerful framework for developing applications powered by LLMs. It's used to chain together different components: LLM calls, document loaders, text splitters, embedding models, vector stores, and prompt templates. LangChain simplifies the implementation of complex workflows like RAG and managing conversational memory.
- Hugging Face Transformers: Provides access to thousands of pre-trained models, including LLMs and sentence transformers. While Ollama serves the main LLM, Transformers might be used directly for specific NLP tasks or for loading embedding models.
- NLTK (Natural Language Toolkit) & spaCy: Foundational Python libraries for various NLP tasks. While the LLM handles much of the high-level understanding, NLTK or spaCy might be used for more granular text pre-processing, such as sentence tokenization for precise chunking, lemmatization, or specialized Named Entity Recognition (NER) if needed beyond the LLM's capabilities.
-
Optical Character Recognition (OCR):
Due to Computational Limitations, we picked the cloud AI (gemini) instead of Local vision language model
Google Gemini API (Vision capabilities): Specifically chosen for its state-of-the-art OCR performance, especially on challenging inputs like handwritten text and complex document layouts often found in prescriptions. Its multimodal capabilities allow it to understand the context of text within an image. This is a cloud-based API, requiring an API key and internet connectivity.
-
Speech Processing:
- OpenAI Whisper: An open-source, highly accurate automatic speech recognition (ASR) model. Used for converting spoken user queries into text. Its robustness across various accents and noisy environments makes it a strong choice.
- gTTS (Google Text-to-Speech) / Browser Web Speech API: For converting chatbot text responses into audible speech. gTTS is a Python library interfacing with Google Translate's TTS engine, while the Web Speech API can be leveraged on the frontend for client-side synthesis. `sounddevice` (Python) might be used for lower-level audio I/O if direct microphone access from the backend is required (less common for web apps).
-
Vector Database:
- Chroma DB: A developer-friendly, open-source vector database. It stores the vector embeddings of document chunks generated by sentence-transformer models. Chroma DB enables efficient semantic similarity searches, which are the core of the RAG system – finding document excerpts most relevant to a user's query. Its ability to run in-memory or persistently, and its ease of integration with LangChain, are key advantages.
-
Supporting Libraries:
- PyTorch: The deep learning framework often underlying Hugging Face Transformers and Whisper models. Required for model inference, especially if running models locally.
- NumPy: Fundamental package for numerical computation in Python, used extensively by AI/ML libraries.
- python-dotenv: Manages environment variables by loading them from a `.env` file, crucial for keeping sensitive information like API keys out of source code.
- Pillow (PIL Fork): Python Imaging Library used for basic image processing tasks (e.g., opening, resizing, format conversion) before sending images to the OCR API or for other manipulations.
- psycopg2-binary: The PostgreSQL adapter for Python, enabling SQLAlchemy to communicate with the PostgreSQL database.
Why This Approach? The Strategic Rationale
This technology stack was deliberately assembled to balance cutting-edge AI capabilities with practical development and deployment considerations. Flask offers a nimble yet powerful backend, avoiding the prescriptive nature of larger frameworks. SQLAlchemy ensures robust and maintainable database interactions. The combination of a locally-hostable LLM (Llama 3.2 via Ollama) with LangChain for orchestration allows for rapid prototyping and iteration of complex AI features while retaining control over the core logic. Google's Gemini API is chosen for its superior OCR, a critical bottleneck for prescription understanding. Chroma DB provides an efficient, easy-to-use vector store essential for effective RAG, which significantly enhances the LLM's factual grounding and ability to leverage user-specific documents. This careful selection aims for a system that is powerful, extensible, relatively cost-effective (by leveraging open-source components where possible), and capable of handling sensitive healthcare data responsibly.
Installation and Setup
To deploy the Intelligence Assistance Chatbot on your local machine for development or testing, follow these comprehensive steps. It's crucial to ensure your system meets the prerequisites for optimal performance, especially concerning AI model inference.
System Requirements:
- Operating System: Linux (recommended for ease of use with many AI tools), macOS, or Windows (with WSL2 for a Linux-like environment often being beneficial).
- Python: Version 3.8 to 3.10 is generally well-supported by the ecosystem. Using a version manager like `pyenv` is advisable.
- Hardware (Critical for LLM & Whisper Performance):
- GPU: An NVIDIA GPU with at least 8GB VRAM is highly recommended for running Llama 3.2 8B and Whisper efficiently. For Llama 3.2 8B, 12GB+ VRAM provides a better experience. Examples: NVIDIA RTX 3060 (12GB), RTX 3080, RTX 4070, or higher. AMD GPUs might work with ROCm support in PyTorch, but NVIDIA with CUDA is more straightforward. Cloud-based GPUs (e.g., Google Colab T4, AWS EC2 P3/G4 instances) are also an option.
- CPU-only: Possible, but inference will be *significantly* slower, potentially making real-time interaction frustrating. A modern multi-core CPU is needed if going this route.
- Memory (RAM): Minimum 16GB. 32GB or more is recommended, especially if running multiple models or handling large documents.
- Disk Space: Approximately 50-70GB free space to accommodate Python dependencies, downloaded AI models (LLMs, embedding models, Whisper can be several GBs each), the ChromaDB vector store (if persistent and large), and PostgreSQL data. SSD is highly recommended for faster load times.
- Internet Connection: Not required, if you are making use of local models either open source or custom fine-tuned. but it is Required for downloading dependencies, models, and for accessing the Gemini API.
Detailed Installation Steps:
-
Install Python: If not already installed, download Python 3.8+ from python.org or use `pyenv`. Ensure Python and `pip` are added to your system's PATH.
# Example with pyenv
pyenv install 3.9.13
pyenv global 3.9.13
-
Clone the Repository (if applicable): If the project is in a Git repository:
git clone <repository_url>
cd <project_directory>
-
Create and Activate a Virtual Environment: This isolates project dependencies.
python -m venv venv
# On Windows:
# venv\Scripts\activate
# On macOS/Linux:
source venv/bin/activate
Your terminal prompt should now be prefixed with `(venv)`.
-
Install Dependencies: The `requirements.txt` file lists all Python packages.
pip install -r requirements.txt
This can take a while, especially for PyTorch if it needs to download CUDA-specific versions. If you have an NVIDIA GPU, ensure PyTorch is installed with CUDA support. You might need to install it separately from pytorch.org if `requirements.txt` specifies a CPU-only version or if you encounter issues.
-
Install FFmpeg: Essential for Whisper and other audio processing tasks (e.g., converting audio formats, resampling).
Download from ffmpeg.org.
**Crucially, add the directory containing the `ffmpeg` executable to your system's PATH environment variable.**
Verify by typing `ffmpeg -version` in a new terminal window.
-
Set Up PostgreSQL:
- Install PostgreSQL (e.g., from postgresql.org or via a package manager like `apt` or `brew`).
- Start the PostgreSQL service.
- Create a database and a user for the application.
-- Example SQL commands (run as postgres superuser, e.g., using psql)
CREATE DATABASE medical_chatbot_db;
CREATE USER chatbot_user WITH PASSWORD 'your_secure_password';
GRANT ALL PRIVILEGES ON DATABASE medical_chatbot_db TO chatbot_user;
-
Set Up Ollama and Download Llama 3.2 8B:
- Download and install Ollama from ollama.ai.
- Pull the Llama 3.2 8B model (ensure you have the correct model tag, e.g., `llama3.2:8b` or similar):
ollama pull llama3.2:8b
- Ensure Ollama is running (typically as a background service). You can test it with `ollama list`.
-
Obtain API Keys and Configure Environment Variables:
Create a `.env` file in the project's root directory. **Never commit `.env` to version control.** Add it to your `.gitignore` file.
#.env file content
GEMINI_API_KEY=your_actual_google_ai_studio_api_key
# Database URL for SQLAlchemy
DATABASE_URL=postgresql://chatbot_user:your_secure_password@localhost:5432/medical_chatbot_db
# Ollama API endpoint if not default
OLLAMA_API_URL=http://localhost:11434/api/generate
# Other sensitive config or app secrets
FLASK_SECRET_KEY=a_very_strong_random_secret_key_for_sessions
# ... any other necessary API keys or configuration ...
Replace placeholders with your actual credentials and keys. Get your Gemini API key from Google AI Studio.
Configuration Requirements (`config.py`):
The `config.py` file typically loads these environment variables and sets other application parameters. Ensure it correctly loads values from `.env` (e.g., using `python-dotenv`). Key configurations to verify in `config.py` or via environment variables:
- `DATABASE_URL`: Connection string for PostgreSQL.
- `OLLAMA_API_URL`: Endpoint for the Llama 3.2 model served by Ollama.
- `GEMINI_API_KEY`: For OCR via Google Gemini.
- `FLASK_SECRET_KEY`: Essential for session management and security in Flask.
- Paths for data storage: `CHROMA_PATH` (if ChromaDB is persistent), `UPLOAD_FOLDER` for user-uploaded files. Ensure these directories exist and are writable by the application.
- RAG parameters: `CHUNK_SIZE`, `CHUNK_OVERLAP` for text splitting.
Post-Installation Tasks & Verification:
-
Database Migrations: If the project uses a migration tool like Flask-Migrate (with Alembic), run the migrations to create the database schema defined in `models.py`.
(venv) flask db upgrade # (or similar command based on project setup)
If not using migrations, you might need to create tables manually or via a script (e.g., `db.create_all()` in Flask-SQLAlchemy for initial setup, but migrations are better for evolution).
-
Run the Flask Application:
(venv) python app2.py
This starts the Flask development server, usually on `http://127.0.0.1:5000/`. Check the terminal output for the exact address and any error messages.
-
Initial Verification:
- Open the application in your web browser.
- Test basic chat functionality. Does the LLM respond?
- Try uploading a simple text document. Can you ask questions about its content?
- Attempt to upload a clear image of a (mock) prescription. Does OCR attempt to process it? (Check logs for Gemini API calls).
- Test voice input/output if implemented.
- Check for any errors in the Flask console or browser developer console.
Troubleshooting: If you encounter issues, check: Python version compatibility, `pip install` logs for errors, GPU driver compatibility with PyTorch/CUDA, Ollama server status, PostgreSQL connection, API key validity, and file/directory permissions.
Codebase Walkthrough
A deep understanding of the project's codebase architecture, key modules, and data flow is essential for effective development, debugging, and contribution. The project is structured to promote modularity, separation of concerns, and maintainability, following common Python web application patterns.
Standard Directory and File Structure:
A well-organized project might look like this (specific names may vary):
.
├── app/ # Main application package
│ ├── __init__.py # Initializes Flask app, extensions, Blueprints
│ ├── main/ # Blueprint for core routes (chat, UI)
│ │ ├── __init__.py
│ │ └── routes.py
│ ├── api/ # Blueprint for API-specific routes
│ │ ├── __init__.py
│ │ └── routes.py # Endpoints for /api/chat, /api/document etc.
│ ├── models.py # SQLAlchemy database models (schema definition)
│ ├── services/ # Business logic, service layer
│ │ ├── chat_service.py
│ │ ├── document_service.py
│ │ ├── ocr_service.py
│ │ └── rag_service.py # Encapsulates RAG logic
│ ├── static/ # Static assets (CSS, JavaScript, images)
│ │ ├── css/
│ │ ├── js/
│ │ └── images/
│ ├── templates/ # HTML templates (Jinja2)
│ └── utils/ # Utility functions, helpers
├── migrations/ # Database migration scripts (if using Flask-Migrate/Alembic)
├── tests/ # Unit and integration tests
│ ├── test_api.py
│ └── test_services.py
├── venv/ # Virtual environment
├── .env # Environment variables (GITIGNORED!)
├── .flaskenv # Flask specific env vars (e.g. FLASK_APP, FLASK_ENV)
├── config.py # Configuration classes (Dev, Prod, Test)
├── requirements.txt # Project dependencies
├── app2.py # Main entry point to run the app (or run.py, wsgi.py)
└── README.md # Project overview and setup
This structure separates concerns: `app/` contains the core application, `migrations/` handles database schema changes, `tests/` for quality assurance, and root files for configuration and execution. Using Flask Blueprints (`app/main/`, `app/api/`) helps organize routes into manageable groups.
Core Components & Their In-depth Roles:
-
Flask Application Factory (`app/__init__.py`):
Often employs the "application factory" pattern. A function (e.g., `create_app()`) initializes the Flask app object, configures it from `config.py`, initializes extensions (SQLAlchemy, JWT, CORS, etc.), and registers Blueprints. This pattern is excellent for testing and managing multiple configurations.
-
Routes and Controllers (e.g., `app/main/routes.py`, `app/api/routes.py`):
These files define the application's endpoints using Flask's `@blueprint.route('/path')` decorator. Controller functions handle incoming HTTP requests, parse data (from forms, JSON payloads, query parameters), interact with service layer modules (`app/services/`) to perform business logic, and formulate HTTP responses (rendering Jinja2 templates for HTML, or returning JSON for APIs). They act as the interface between the web and the application's core logic.
-
SQLAlchemy Models (`app/models.py`):
Defines the database schema using Python classes that inherit from SQLAlchemy's `db.Model`. Each class maps to a table, and class attributes map to columns with specific data types (Integer, String, Text, DateTime, Boolean, ForeignKey for relationships). Relationships (one-to-many like `User` to `Chat`, many-to-many like `Document` to `Tag`) are defined using `db.relationship()`. These models provide an object-oriented way to query and manipulate data, abstracting SQL. Important aspects include defining primary keys, foreign keys, indexes for performance, and constraints.
-
Service Layer (e.g., `app/services/chat_service.py`, `rag_service.py`):
This layer encapsulates the core business logic. For example, `ChatService` might handle message processing, interaction with the LLM, and saving chat history. `RAGService` would manage document ingestion (chunking, embedding, storing in ChromaDB) and query-time retrieval of relevant context. Services interact with `models.py` for database operations and external APIs (Ollama, Gemini). This separation keeps controllers lean and logic reusable.
-
RAG Manager/Service (`app/services/rag_service.py` or `rag.py`):
Crucial for grounding LLM responses. Key responsibilities:
- Document Loading & Preprocessing: Using LangChain document loaders for various file types.
- Text Splitting: Employing strategies like `RecursiveCharacterTextSplitter` to break documents into manageable, semantically meaningful chunks. The choice of `chunk_size` and `chunk_overlap` is critical and often requires experimentation to balance context window limits with information completeness.
- Embedding Generation: Using a sentence-transformer model (e.g., from Hugging Face) to convert text chunks into numerical vectors.
- Vector Storage: Interfacing with Chroma DB to store embeddings and associated metadata (e.g., document source, chunk ID).
- Similarity Search/Retrieval: Given a user query, embed it and perform a similarity search (e.g., cosine similarity) in Chroma DB to find the top-k most relevant chunks.
- Context Formatting: Preparing the retrieved chunks as context to be prepended to the LLM prompt.
-
OCR Processor/Service (`app/services/ocr_service.py` or `ocr_processor.py`):
Handles text extraction from images. This involves:
- Receiving image data (e.g., uploaded file).
- Optional image pre-processing (resizing, denoising, binarization using Pillow/OpenCV) to improve OCR accuracy, though modern APIs like Gemini often handle this well.
- Interfacing with the Gemini API: sending the image (e.g., as base64 encoded string or bytes) and handling the API response, which contains the extracted text and potentially bounding box information.
- Error handling for API calls (network issues, rate limits, invalid API key).
-
Configuration (`config.py`):
Defines different configuration environments (e.g., `DevelopmentConfig`, `ProductionConfig`, `TestingConfig`) as Python classes. Common settings include `SECRET_KEY`, `SQLALCHEMY_DATABASE_URI`, API keys, debug flags, and custom application settings. It often uses `os.getenv()` to load values from environment variables, allowing for secure and flexible configuration across deployments.
-
Static Assets & Templates (`app/static/`, `app/templates/`):
`static/` holds CSS files for styling, JavaScript for client-side interactivity (e.g., AJAX calls to API, dynamic UI updates, theme toggle), and images. `templates/` contains HTML files, typically using the Jinja2 templating engine, which Flask integrates seamlessly. Jinja2 allows embedding Python-like expressions and logic within HTML to render dynamic content.
Key Code Snippets and Design Patterns Illustrated:
-
Flask Route with Service Interaction (Simplified):
# In app/api/routes.py
from flask import Blueprint, request, jsonify
from app.services.chat_service import process_user_message
from app.models import Chat # Assuming Chat model exists
api_bp = Blueprint('api', __name__, url_prefix='/api')
@api_bp.route('/chat/<int:chat_id>/message', methods=['POST'])
# @jwt_required() # If authentication is needed
def send_chat_message(chat_id):
# user = get_jwt_identity() # Get user from JWT
data = request.get_json()
if not data or 'message' not in data:
return jsonify({"error": "Missing message"}), 400
user_message = data['message']
# Basic authorization check (example)
# chat = Chat.query.get_or_404(chat_id)
# if chat.user_id != user.id:
# return jsonify({"error": "Unauthorized"}), 403
try:
bot_response, updated_history = process_user_message(chat_id, user_message)
return jsonify({
"bot_response": bot_response,
"history": [msg.to_dict() for msg in updated_history] # Assuming a to_dict() method on Message model
}), 200
except Exception as e:
# Log the exception e
return jsonify({"error": "Failed to process message"}), 500
This illustrates request parsing, interaction with a service (`process_user_message`), error handling, and JSON response generation. Authentication (`@jwt_required`) and authorization would be critical additions.
-
SQLAlchemy Model with Relationships:
# In app/models.py
from app import db # Assuming db is the SQLAlchemy instance from app/__init__.py
from datetime import datetime
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
# ... other fields like hashed_password ...
chats = db.relationship('Chat', backref='user', lazy=True) # One-to-Many with Chat
class Chat(db.Model):
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)
created_at = db.Column(db.DateTime, default=datetime.utcnow)
title = db.Column(db.String(200))
messages = db.relationship('Message', backref='chat', lazy='dynamic', cascade="all, delete-orphan") # One-to-Many with Message
class Message(db.Model):
id = db.Column(db.Integer, primary_key=True)
chat_id = db.Column(db.Integer, db.ForeignKey('chat.id'), nullable=False)
sender = db.Column(db.String(10)) # 'user' or 'bot'
content = db.Column(db.Text, nullable=False)
timestamp = db.Column(db.DateTime, default=datetime.utcnow)
# Potentially add metadata like sources used for RAG response
# metadata = db.Column(db.JSON)
def to_dict(self): # Example method for serialization
return {
'id': self.id, 'sender': self.sender, 'content': self.content,
'timestamp': self.timestamp.isoformat()
}
Demonstrates defining tables, columns, primary/foreign keys, and relationships (`user.chats`, `chat.messages`). `lazy='dynamic'` for `messages` means it returns a query object, useful for further filtering. `cascade="all, delete-orphan"` ensures messages are deleted if their parent chat is deleted.
-
RAG Retrieval Snippet in a Service:
# In app/services/rag_service.py (conceptual)
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings # More specific
from langchain.text_splitter import RecursiveCharacterTextSplitter
# from app import db # For interacting with document metadata models
class RAGService:
def __init__(self, chroma_path, embedding_model_name, chunk_size, chunk_overlap):
self.embedding_model = HuggingFaceEmbeddings(model_name=embedding_model_name)
self.vector_store = Chroma(persist_directory=chroma_path, embedding_function=self.embedding_model)
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# self.collection_name = "medical_documents" # If using named collections in Chroma
def add_document_to_vector_store(self, text_content, doc_metadata):
chunks = self.text_splitter.split_text(text_content)
# Create list of LangChain Document objects for Chroma
# lc_documents = [Document(page_content=chunk, metadata=doc_metadata) for chunk in chunks]
# self.vector_store.add_documents(lc_documents, collection_name=self.collection_name)
# self.vector_store.persist() # If using persistence
pass # Simplified
def get_relevant_context(self, query_text, n_results=3):
# results = self.vector_store.similarity_search(query_text, k=n_results, collection_name=self.collection_name)
# context_str = "\n\n".join([doc.page_content for doc in results])
# return context_str
pass # Simplified
Highlights instantiation of embedding models, vector stores, and text splitters. The actual addition and querying would involve LangChain's `Document` objects and the `add_texts` or `similarity_search` methods of the vector store. Metadata associated with chunks is vital for filtering or citing sources.
Navigating this structure involves understanding how requests flow from routes to services, how services use models for data persistence, and how external APIs or complex logic (like RAG) are encapsulated within services. The use of dependency injection (passing configurations or other services to classes) is also a common and good practice.
Usage Instructions
Once the Intelligence Assistance Chatbot is successfully installed, configured, and running, interacting with its features is designed to be intuitive through its web interface. This section provides guidance on how to effectively use the application and troubleshoot common operational scenarios.
Running the Application (Recap):
Ensure your virtual environment is active and all configurations (especially `.env` file with API keys and database URL) are correctly set. Start the Flask application from the project's root directory:
(venv) python app2.py
The terminal will indicate the address where the application is being served (typically `http://127.0.0.1:5000`). For production, a robust WSGI server like Gunicorn is used (see Deployment section).
Interacting with the Chatbot via Web Interface:
Open your web browser and navigate to the application's URL.
❮
❯
Screenshots of the Chatbot Interface in use. (Use arrows to navigate)
-
Starting a New Chat: The interface should allow you to start a new chat session. This isolates conversation contexts.
-
Text-Based Queries:
- Type your medical questions, symptom descriptions, or requests for information into the chat input box. Press Enter or click the send button.
- Example Queries:
- "What is hypertension?"
- "My prescription says 'Metformin 500mg BID'. What does BID mean?"
- "I've been feeling tired and have a persistent cough for a week." (Expect informational response, not diagnosis)
- If a document about diabetes was uploaded: "What are common complications of diabetes mentioned in my document?"
- The chatbot, powered by Llama 3.2 and RAG, will process your input and generate a response. Be mindful that LLMs can sometimes be verbose or, despite RAG, misinterpret complex queries. Rephrasing or breaking down complex questions can help.
-
Uploading Documents for Analysis:
- Locate the document upload feature (e.g., an "Upload Document" button).
- Select supported file types: text files (.txt, .md) or images of prescriptions/documents (.png, .jpg, .jpeg).
- Upon successful upload, the system processes the document:
- Images are sent to the Gemini API for OCR.
- Text content is chunked, embedded, and indexed in Chroma DB.
- You can then ask questions specifically related to the content of the uploaded document(s) within the current chat session (or as per system design for document persistence).
- "Summarize the key findings from the uploaded lab report."
-
Managing Vitals and Appointments:
- Navigate to dedicated sections for "Vital Signs" or "Appointments."
- Follow on-screen forms to input data (e.g., temperature values, blood pressure readings, appointment details).
- View historical vital signs data or upcoming appointments.
-
Voice Interaction (Speech-to-Text / Text-to-Speech):
- If enabled, look for a microphone icon to activate STT. Click it, grant microphone permission if prompted by the browser, and speak your query. Whisper will transcribe it.
- Chatbot responses may be automatically read aloud (TTS) if this feature is active.
-
Managing Chat History: The interface should list past chat sessions, allowing you to revisit or delete them.
Understanding Chatbot Responses & Limitations:
- Informational, Not Diagnostic: Crucially, remember this tool provides information and assistance, **not medical diagnoses or treatment advice.** Always consult a qualified healthcare professional for medical concerns.
- RAG-Grounded Responses: When querying about uploaded documents, the RAG system strives to base answers on that content. However, the LLM still synthesizes the final response.
- Medical Abbreviation Expansion: If an abbreviation isn't in its lexicon, it might not be expanded or could be misinterpreted.
- OCR Accuracy: While Gemini is powerful, OCR on very poor handwriting or complex layouts can still have errors. Double-check critical information (like dosages) against the original prescription if unsure.
Configuration for Different Environments (Recap):
The application's behavior can be tailored via `config.py` and environment variables:
- Development (`FLASK_ENV=development`): Enables debug mode (detailed error pages, auto-reloader). Uses local development settings (e.g., local DB, test API keys if available).
- Production (`FLASK_ENV=production`): Disables debug mode. Uses production-grade settings (e.g., production database URI, actual API keys). Environment variables are paramount for security here.
Troubleshooting Common Operational Issues:
If you encounter problems while using the application:
-
Chatbot Not Responding / Extremely Slow:
- Check Flask Server: Is the `python app2.py` process still running in your terminal? Any error messages displayed?
- Ollama Service: Is the Ollama service running? (e.g., `ollama list` in terminal). Is the Llama 3.2 model fully downloaded and available? Check Ollama logs if accessible.
- GPU/CPU Usage: Monitor system resources. High CPU/GPU usage might indicate slow model inference. If on CPU, expect slowness.
- Network Connectivity: Required for Gemini API. Check internet connection.
- Browser Developer Console: Open it (usually F12) and check for JavaScript errors or failed network requests (e.g., to your Flask API endpoints).
-
Document Upload Fails or Processing Errors:
- File Type/Size: Check if the file type is supported and within any size limits defined in the application.
- Server Logs (`app2.py` output): Look for errors during file saving, OCR processing (Gemini API errors like "API key invalid", "Quota exceeded", "Unsupported image format"), or RAG indexing.
- `uploads/` Directory: Ensure this directory exists in the project root (or configured path) and that the application has write permissions to it.
-
OCR Quality Issues with Prescriptions:
- Image Quality: Ensure uploaded images are clear, well-lit, and reasonably flat. Very blurry, skewed, or low-resolution images will degrade OCR.
- Gemini API Status: Check if the Gemini API service is operational.
- API Key: Verify `GEMINI_API_KEY` is correct and has necessary permissions/quotas in your Google AI Platform project.
-
Speech-to-Text (STT) or Text-to-Speech (TTS) Not Working:
- FFmpeg: Confirm FFmpeg is correctly installed and in the system PATH.
- Microphone/Speaker Permissions: Ensure your browser has permission to access the microphone. Check system audio settings.
- Whisper Model: If Whisper is run locally, ensure the model files are downloaded and accessible. Check for related errors in server logs.
- TTS Service: If using gTTS, ensure internet connectivity. If using browser Web Speech API, check browser compatibility.
-
Database Errors (e.g., "Cannot connect to server"):
- PostgreSQL Service: Is the PostgreSQL server running?
- `DATABASE_URL` in `.env`/`config.py`: Double-check host, port, database name, username, and password for typos.
- Firewall: Ensure no firewall is blocking connections to the PostgreSQL port (default 5432) from the machine running Flask.
- Database Migrations: If you see errors like "table not found," ensure migrations have been run correctly after any model changes.
- "Context Length Exceeded" or Similar LLM Errors:
- This can happen if the combined prompt (system message, history, RAG context, user query) is too long for Llama 3.2's context window.
- Solutions involve better history summarization, more selective RAG context, or chunking user input if it's excessively long. The application should ideally handle this gracefully.
For persistent issues, detailed logs from the Flask application, Ollama, PostgreSQL, and the browser's developer console are invaluable for diagnosis.
Testing Strategy and Execution
A robust and multi-layered testing strategy is paramount for ensuring the reliability, correctness, and stability of the Intelligence Assistance Chatbot, especially given its handling of potentially sensitive information and complex AI components. The project employs a combination of unit, integration, and potentially end-to-end (E2E) tests, primarily using Python's testing ecosystem.
Core Testing Philosophy:
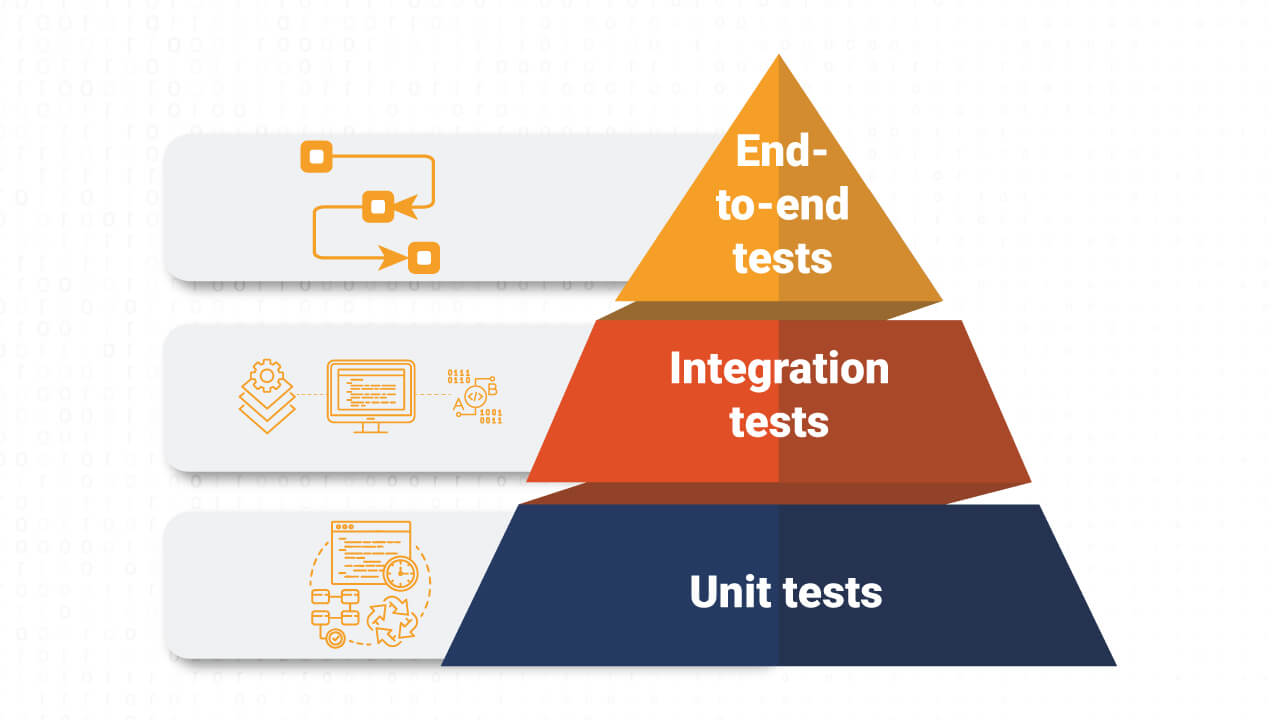
The testing approach follows the "testing pyramid" principle: a broad base of fast unit tests, a smaller layer of integration tests, and an even smaller (if present) set of E2E tests. The aim is to catch bugs early, ensure individual components work as expected, and verify that these components interact correctly.
Illustrating the Testing Pyramid Concept.
Testing Frameworks and Tools:
- pytest: The primary testing framework. Chosen for its expressive syntax, powerful fixture system (for managing test setup/teardown, e.g., database connections, mock objects), extensive plugin ecosystem, and ease of use. Test files are typically named `test_*.py` and test functions `test_*()`.
- unittest (and `unittest.mock`): Python's built-in framework. While `pytest` can run `unittest`-style tests, `unittest.mock` (or `pytest-mock` which wraps it) is indispensable for creating mock objects and patching. Mocking allows isolating units of code by replacing external dependencies (like API calls, database interactions, file system operations) with controllable test doubles.
- Flask-Testing (or Flask's `test_client`): Provides utilities for testing Flask applications. The `test_client` simulates HTTP requests to Flask routes without needing to run a live server, allowing testing of route handlers, request parsing, and response generation.
- pytest-cov: A `pytest` plugin for measuring code coverage. It indicates what percentage of the codebase (lines, branches) is executed by the tests, helping identify untested areas.
- Faker (Optional): Useful for generating realistic fake data (names, addresses, text) for tests.
- Hypothesis (Optional): For property-based testing, generating a wide range of inputs to test functions against specified properties.
Types of Tests Implemented:
- Unit Tests:
- Focus: Test individual functions, methods, or classes in isolation.
- Examples:
- Testing a utility function that formats dates.
- Testing a method in `ChatService` that constructs a prompt for the LLM, mocking the actual LLM call.
- Testing a text chunking function in `RAGService` with various input texts.
- Testing validation logic in a form or model.
- Key Technique: Extensive use of mocking to replace dependencies. For instance, when testing `ocr_service.py`, the call to the Gemini API would be mocked to return predefined responses, allowing tests for how the service handles successful OCR, API errors, or empty results.
- Integration Tests:
- Focus: Test the interaction between multiple components or services.
- Examples:
- Testing a Flask API route for sending a chat message: This involves the route handler, `ChatService`, interaction with mocked LLM/RAG services, and potentially interaction with a test database to verify message storage.
- Testing the document upload and RAG pipeline: Uploading a test document via the `test_client`, verifying it's processed by `DocumentService` and `RAGService`, and then querying the (mocked or test) vector store.
- Testing database interactions: Verifying that SQLAlchemy models correctly save and retrieve data from a dedicated test database.
- Considerations: These tests are slower than unit tests as they involve more components. A test database (e.g., a separate PostgreSQL instance or an in-memory SQLite for faster tests, if compatible) is often used, and fixtures manage its setup and teardown for each test or session. External API calls (Ollama, Gemini) are still typically mocked to avoid flakiness and cost, unless specifically testing the direct API integration with stubs.
- End-to-End (E2E) Tests (Less Frequent, Higher Level):
- Focus: Test the entire application flow from the user's perspective, often involving the UI.
- Tools: Selenium, Playwright, or Cypress (if a JavaScript frontend framework is heavily used).
- Example: A test script that opens a browser, navigates to the chat page, types a message, uploads a document, asks a question about it, and verifies the UI updates correctly.
- Challenges: Slowest to run, most brittle (prone to break with UI changes), and complex to set up. Used sparingly for critical user flows. For this project, a focus on strong API-level integration tests might be more pragmatic initially.
How to Run Tests:
Tests are typically located in a `tests/` directory. Ensure your virtual environment is active and test-specific configurations (e.g., test database URI) are set up (often via fixtures or environment variables like `FLASK_ENV=testing`).
- Run all tests:
(venv) python -m pytest tests/ -v
The `-v` (verbose) flag shows individual test names and results. `-s` can show print statements.
- Run tests in a specific file or directory:
(venv) python -m pytest tests/services/test_chat_service.py -v
- Run a specific test function by name (using `-k` keyword expression):
(venv) python -m pytest -k "test_prescription_parsing" -v
- Run tests with coverage report:
(venv) python -m pytest --cov=app --cov-report=html tests/
This runs tests, measures coverage for the `app` directory, and generates an HTML report in an `htmlcov/` directory. Open `htmlcov/index.html` in a browser to see detailed line-by-line coverage.
Writing Effective Tests:
When contributing, adhere to these best practices:
- Test File Structure: Mirror the application structure within `tests/` (e.g., `tests/services/test_rag_service.py` for `app/services/rag_service.py`).
- Clear Naming: Test function names should clearly describe what they are testing (e.g., `test_process_user_message_with_rag_context_success`).
- AAA Pattern: Arrange (set up test conditions), Act (execute the code under test), Assert (verify the outcome).
- Pytest Fixtures (`@pytest.fixture`): Use extensively for reusable setup code:
Fixture scopes (`function`, `class`, `module`, `session`) control how often setup/teardown runs.
- Effective Mocking: Use `mocker` (from `pytest-mock`) or `unittest.mock.patch` to replace external dependencies.
def test_ocr_with_mocked_gemini(mocker, ocr_service_instance):
mock_gemini_response = {"textAnnotations": [{"description": "Sample OCR text"}]}
mocker.patch('google.generativeai.GenerativeModel.generate_content', return_value=MagicMock(text="Sample OCR text")) # Path to actual API call
result = ocr_service_instance.process_image("fake_image_bytes")
assert result == "Sample OCR text"
- Test Coverage, Not Just Quantity: Focus on testing different logical paths, edge cases (empty inputs, invalid data, null values), and error handling scenarios, not just "happy path" execution. Aim for high branch coverage.
- Independent Tests: Each test should be independent and not rely on the state or outcome of other tests. Proper fixture usage helps achieve this.
- Readability: Tests are also documentation. Write clear, understandable tests.
Test Coverage Goals:
While 100% coverage is often not a practical or cost-effective goal, striving for high coverage (e.g., 85-90%+) for critical business logic (services, models) is essential. Coverage reports highlight untested code, prompting further test development. However, high coverage doesn't guarantee bug-free code; the quality and diversity of assertions are equally important. It primarily shows what code *has been executed*, not if it *behaved correctly in all circumstances*.
Deployment Strategy and CI/CD Pipeline
Deploying the Intelligence Assistance Chatbot effectively requires a well-thought-out strategy to move the application from a development environment to a live, accessible production server. A Continuous Integration/Continuous Deployment (CI/CD) pipeline automates this process, ensuring consistency, reliability, and speed in releases.
Deployment Options & Considerations:
The project is designed for flexibility in deployment:
-
Local Development/Testing Server:
-
Platform-as-a-Service (PaaS): E.g., Heroku, Render, AWS Elastic Beanstalk, Google App Engine.
- Pros: Simplifies infrastructure management. Handles scaling, load balancing, and deployment workflows to a large extent.
- Process: Typically involves a `Procfile` (e.g., `web: gunicorn app:create_app()`), `requirements.txt`, and configuration via environment variables set on the PaaS dashboard. Database services are often provided as add-ons.
- Considerations: Cost, limitations of the free/hobby tiers, region availability, specific platform requirements for file system access (ephemeral on Heroku). Running Ollama might require a separate VPS or a PaaS that supports custom Docker images with GPU access, or using a cloud LLM API instead.
-
Containerization with Docker: Highly recommended for portability, consistency, and scalability.
- `Dockerfile`:** Defines the image.
# Example Dockerfile (adjust for your project)
FROM python:3.9-slim
WORKDIR /app
# Set environment variables (can be overridden at runtime)
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV FLASK_APP app:create_app()
ENV FLASK_ENV production
# For Gunicorn
ENV PORT 5000
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# Ensure uploads directory exists if needed inside container (or use volume)
# RUN mkdir -p /app/uploads
EXPOSE $PORT
# CMD instruction to run Gunicorn
CMD ["gunicorn", "--workers", "4", "--bind", "0.0.0.0:$PORT", "app:create_app()"]
- Deployment: Docker images can be run directly on a server with Docker installed, or deployed to container orchestration platforms (Kubernetes, Docker Swarm) or cloud container services (AWS ECS/EKS, Google Kubernetes Engine, Azure Kubernetes Service).
- Ollama in Docker: Ollama itself can be run in a Docker container, potentially on the same host or a separate one, and networked with the application container. If GPU access is needed for Ollama, the Docker runtime and host need to be configured for NVIDIA GPU support (nvidia-docker).
-
Virtual Private Server (VPS) / Bare Metal: E.g., AWS EC2, DigitalOcean Droplets, Linode.
- Pros: Full control over the environment.
- Cons: More setup and maintenance (OS updates, security patching, web server configuration like Nginx/Apache as a reverse proxy, process management with systemd/supervisor).
- Process: Set up Python, PostgreSQL, Ollama (with GPU drivers if needed), clone the app, install dependencies, configure a reverse proxy (Nginx) to serve the Gunicorn process, manage SSL certificates (e.g., Let's Encrypt).
Key Production Considerations:
- Database: Use a managed PostgreSQL service (AWS RDS, Google Cloud SQL) or a robust self-hosted setup.
- Ollama/LLM Hosting: Decide whether to self-host Ollama (requires appropriate hardware, especially GPU) or use a managed LLM API endpoint (adds cost and external dependency).
- Static Files & Media: For performance, serve static files (CSS, JS) via Nginx or a Content Delivery Network (CDN). User-uploaded files (media) should ideally be stored in a dedicated object storage service (AWS S3, Google Cloud Storage) rather than the application server's local file system, especially in containerized or PaaS environments.
- Logging & Monitoring: Implement comprehensive logging (e.g., to files, centralized logging services like ELK stack or Datadog) and application performance monitoring (APM).
- Security: HTTPS enforced everywhere, regular security updates, firewall configuration.
CI/CD Pipeline Implementation:
A CI/CD pipeline automates the build, test, and deployment lifecycle. Tools: GitHub Actions, GitLab CI/CD, Jenkins, CircleCI.
Typical CI/CD Workflow (e.g., using GitHub Actions, triggered on push to `main` or PRs):
- Trigger: Code push to specific branches (e.g., `develop`, `main`) or on pull request creation.
- Checkout Code: Fetch the latest version of the repository.
- Set Up Environment:
- Specify Python version.
- Cache dependencies (e.g., `pip` cache) to speed up subsequent runs.
- Install dependencies from `requirements.txt`.
- Linting and Code Formatting:
- Run Tests:
- Execute all unit and integration tests using `pytest`.
pytest --cov=app tests/
- Set up necessary services for testing (e.g., a PostgreSQL service container if integration tests hit a real DB, mock API services). Environment variables for test configuration are crucial here.
- Fail the build if any tests fail or if coverage drops below a defined threshold.
- Security Scans (Optional but Recommended):
- Static Application Security Testing (SAST) tools like Bandit: `bandit -r app/`.
- Dependency vulnerability scanning (e.g., `safety check -r requirements.txt` or GitHub's Dependabot alerts).
- Build Artifacts (if applicable):
- If using Docker, build the Docker image: `docker build -t myapp-image:${{ github.sha }} .`
- Push the Docker image to a container registry (Docker Hub, AWS ECR, Google Container Registry): `docker push myapp-image:${{ github.sha }}`.
- Continuous Deployment (CD) to Staging/Production (Conditional on successful CI):
- Staging Deployment: Automatically deploy to a staging environment (a replica of production for final testing) on pushes to a `develop` or `staging` branch.
- Production Deployment:
- Often triggered manually after successful staging tests, or automatically on merges to the `main` branch (for true Continuous Deployment).
- Deployment script executes:
- Pulls the new Docker image on production servers.
- Updates the running application (e.g., `docker-compose up -d --force-recreate`, Kubernetes `kubectl apply -f deployment.yaml`, PaaS CLI commands like `heroku deploy`).
- Runs database migrations: `flask db upgrade` (needs to be done carefully in production).
- Performs health checks post-deployment.
- Notifications: Notify developers of build/deployment status (success or failure) via Slack, email, etc.
The CI/CD configuration is usually defined in a YAML file (e.g., `.github/workflows/main.yml` for GitHub Actions).
Rollback Strategy:
A critical part of deployment is the ability to quickly revert to a previous stable version if a new deployment introduces critical issues.
- Application Rollback:
- Docker/Containers: Re-deploy the previous Docker image tag. Orchestration platforms usually have built-in rollback features.
- PaaS: Most PaaS providers offer a way to redeploy a previous release version.
- Database Rollback:
- This is more complex. If a deployment included breaking database schema changes (migrations), rolling back the application code might require also downgrading the database schema using migration tool commands (e.g., `flask db downgrade`). This must be tested thoroughly, as downgrades can be risky and potentially lead to data loss if not handled correctly.
- Regular database backups are essential. For critical issues, restoring from a backup might be necessary (a last resort).
- Process: Have a documented rollback procedure. Monitoring and alerting systems should quickly identify issues post-deployment to trigger a rollback if needed.
Security Considerations and Best Practices
Given the potential for handling sensitive medical information (even if anonymized or user-provided), security is a non-negotiable, paramount concern. The project must incorporate robust security measures at multiple layers to protect user data, maintain privacy, and ensure application integrity.
Authentication & Authorization:
Controlling access is the first line of defense.
- Strong User Authentication:
- Password Hashing: Never store passwords in plain text. Use strong, adaptive, salted hashing algorithms like Argon2 (preferred), scrypt, or bcrypt. Flask-Bcrypt or Werkzeug's security helpers can be used.
from werkzeug.security import generate_password_hash, check_password_hash
hashed_pw = generate_password_hash("plain_text_password")
is_correct = check_password_hash(hashed_pw, "user_entered_password")
- Multi-Factor Authentication (MFA/2FA) - Future Enhancement: For increased security, consider implementing MFA using TOTP (Time-based One-Time Password) authenticators like Google Authenticator or Authy.
- JWT-based Session Management (for APIs):
- JSON Web Tokens (JWTs) are commonly used for stateless authentication in APIs. Upon login, the server issues an access token (short-lived) and potentially a refresh token (long-lived, stored securely by the client).
- Flask-JWT-Extended is a popular Flask extension.
- Access Tokens: Included in the `Authorization: Bearer ` header of API requests. Validated by the server on each protected endpoint.
- Refresh Tokens: Used to obtain new access tokens without requiring re-login. Must be handled securely (e.g., stored in HttpOnly cookies for web clients if not a pure SPA).
- Token Revocation/Blacklisting: Implement a mechanism to invalidate tokens (e.g., on logout, password change) by maintaining a blacklist (e.g., in Redis or database).
- Role-Based Access Control (RBAC):
- Define roles (e.g., `patient`, `admin`, potentially `caregiver` in future). Assign permissions to roles. Users are assigned roles.
- Enforce authorization checks on routes and service methods to ensure users can only access data and perform actions permitted by their role (e.g., a patient can only see their own chat history and medical data). This involves checking the current user's identity and roles against the resource being accessed.
- Secure Session Management (for Web UI):
- If using traditional Flask sessions (cookie-based), ensure the `SECRET_KEY` is strong and kept confidential. Use `SESSION_COOKIE_SECURE=True`, `SESSION_COOKIE_HTTPONLY=True`, and `SESSION_COOKIE_SAMESITE='Lax'` or `'Strict'`.
- Implement session timeouts (automatic logout after inactivity).
Data Security & Privacy:
Protecting data at rest, in transit, and during processing.
- Encryption in Transit:
- HTTPS Everywhere: Enforce HTTPS for all communication between clients and the server. Use a reverse proxy like Nginx to terminate SSL/TLS and manage certificates (e.g., free certificates from Let's Encrypt via Certbot). Flask-Talisman can help enforce HTTPS and set security headers.
- Encryption at Rest:
- Database Encryption: Modern managed database services (AWS RDS, Google Cloud SQL) offer transparent data encryption (TDE) for data at rest. If self-hosting PostgreSQL, explore filesystem-level encryption or pgcrypto for column-level encryption of highly sensitive fields.
- Sensitive Fields: For specific highly sensitive data within the database (e.g., extracted prescription content if not anonymized, PII), consider application-level encryption using libraries like `cryptography` (AES-256). Key management becomes critical here (e.g., using HashiCorp Vault or cloud KMS).
- Uploaded Files: If storing uploaded medical documents, ensure the storage (e.g., AWS S3) is configured for server-side encryption.
- Environment Variables for Secrets: All credentials (database passwords, API keys, `SECRET_KEY`) MUST be stored in environment variables (loaded via `.env` in dev, set directly in prod environment), never hardcoded in source code. Ensure `.env` is in `.gitignore`.
- Data Minimization & Anonymization:
- Collect and store only the data absolutely necessary for the application's functionality.
- Where possible, consider anonymizing or pseudonymizing data, especially if used for analytics or model training in the future. This is complex for medical data.
- Regular Security Audits & Penetration Testing:
- Periodically conduct security code reviews (manual and automated with SAST tools like Bandit).
- Consider third-party penetration testing for production systems handling sensitive data.
- Compliance (HIPAA, GDPR - if applicable): If the application handles identifiable health information and targets users in relevant jurisdictions, strict adherence to regulations like HIPAA (US) or GDPR (EU) is mandatory. This has significant implications for data handling, consent, audit trails, and security measures. This project, as described for general information, might not directly fall under these if it avoids PII, but it's a critical consideration for any real-world healthcare application.
Common Web Application Vulnerabilities and Mitigations:
-
SQL Injection (SQLi):
- Mitigation: Primarily by using an ORM like SQLAlchemy, which uses parameterized queries (prepared statements) that separate SQL logic from user data. Avoid constructing SQL queries by string concatenation with user input. Validate and sanitize all input that might be used in database queries, even with an ORM.
-
Cross-Site Scripting (XSS): Malicious scripts injected into web pages.
- Mitigation:
- Output Escaping: Jinja2 (Flask's default templating engine) auto-escapes by default, which helps. Ensure this is not disabled.
- Content Security Policy (CSP): Implement a strong CSP header to restrict where scripts can be loaded from and executed.
- Sanitize User Input: If displaying user-generated HTML content, use libraries like Bleach to sanitize it, allowing only safe tags and attributes.
- Avoid using `innerHTML` with unsanitized user data in JavaScript.
-
Cross-Site Request Forgery (CSRF): Trick a user's browser into making unintended requests.
- Mitigation: Use Flask-WTF or similar libraries that generate and validate CSRF tokens for all state-changing requests (POST, PUT, DELETE). Ensure tokens are unique per session and checked on the server.
-
Insecure Direct Object References (IDOR): Accessing resources by guessing IDs.
- Mitigation: Implement strong authorization checks. Always verify that the authenticated user has permission to access or modify the requested resource (e.g., `chat = Chat.query.get(chat_id); if chat.user_id != current_user.id: abort(403)`).
-
Security Misconfiguration: Default credentials, unnecessary services enabled, verbose error messages revealing internal details.
- Mitigation: Harden server configurations, change all default credentials, disable unused features/ports, configure Flask `DEBUG=False` in production, use custom error pages.
- Data Leakage & Information Exposure:
- CORS Policy: Configure Cross-Origin Resource Sharing (CORS) strictly (e.g., using Flask-CORS) to allow API requests only from authorized origins.
- Rate Limiting: Implement rate limiting (e.g., using Flask-Limiter) on API endpoints and login attempts to prevent brute-force attacks and DoS.
- Logging: Log security-relevant events (logins, failed logins, access denials, critical errors) but avoid logging sensitive data like passwords or full API keys in logs. Review logs regularly.
Security Best Practices Applied Throughout Development:
- Principle of Least Privilege: Application processes, database users, and API clients should only have the minimum permissions necessary.
- Input Validation: Validate ALL input from users or external systems on the server-side (type, length, format, range). Do not trust client-side validation alone.
- Regular Dependency Updates: Keep all libraries, frameworks, OS, and database software up-to-date with security patches. Use tools like Dependabot (GitHub) or `pip-audit` to monitor for vulnerabilities in dependencies.
- Secure Software Development Lifecycle (SSDLC): Integrate security considerations into every phase of development, from design to deployment and maintenance.
- Error Handling: Implement robust error handling that fails securely, logs detailed error information for administrators, but does not expose sensitive internal details to users.
Future Improvements & Strategic Roadmap
The Intelligence Assistance Chatbot Project is envisioned as an evolving platform. The current feature set provides a solid foundation, but the roadmap includes several exciting enhancements to expand its capabilities, improve user experience, and broaden its impact in aiding health information comprehension.
High-Priority Upcoming Features:
Development efforts are focused on or planned for these key areas:
-
Multi-language Prescription & Query Support:
- Goal: Enable the system to process prescriptions and understand user queries in languages beyond English (e.g., Spanish, French, German, Hindi).
- Technical Challenges: Requires OCR models (Gemini supports many languages) and LLMs (Llama 3.2 has multilingual capabilities, but quality varies) proficient in target languages. Abbreviation lexicons and NLP pre-processing would need localization. UI internationalization (i18n) is also needed.
- Impact: Massively increases accessibility and usability for a global audience.
-
Automated Drug Interaction Checker:
- Goal: Integrate a module to analyze a user's medication list (from prescriptions or manual input) and check for potential adverse drug-drug interactions, drug-food interactions, or contraindications based on user-provided conditions.
- Technical Challenges: Requires a reliable, up-to-date drug interaction database/API (e.g., NIH's RxNav, OpenFDA, commercial APIs like Medscape or Epocrates). Logic for interpreting interaction severity and presenting clear, actionable warnings is complex. This feature carries significant responsibility and must be carefully validated.
- Impact: Provides a critical safety feature, helping users and caregivers identify potential risks. Must clearly state it's not a substitute for pharmacist/doctor advice.
-
Basic Telemedicine Platform Integration Hooks:
- Goal: Explore initial integrations with telemedicine platforms, potentially allowing users to (with explicit consent) share summarized health data or chatbot interaction summaries with their providers, or receive post-consultation information via the chatbot.
- Technical Challenges: Requires understanding telemedicine API capabilities (e.g., FHIR-based APIs if available), secure authentication and authorization mechanisms, and robust data privacy controls. Starting with simple information hand-offs would be pragmatic.
- Impact: Bridges the gap between self-management tools and professional healthcare, fostering better continuity of care.
-
Enhanced Symptom Analysis with Differential Context:
- Goal: Improve the chatbot's ability to engage in more nuanced, context-aware conversations about symptoms. While not providing diagnoses, it could offer more detailed information about conditions associated with a *combination* of symptoms, cite sources for this information (via RAG), and better guide users on when specific symptom patterns warrant urgent medical attention.
- Technical Challenges: Requires a more sophisticated RAG knowledge base curated from reputable medical sources (e.g., Mayo Clinic, NHS, MedlinePlus). Prompt engineering to elicit detailed symptom information and present potential (not definitive) associations carefully is key. Ethical considerations are paramount.
- Impact: Offers more valuable informational support for users trying to understand their symptoms before seeking professional help.
-
Integration with Wearable Devices & Health Platforms:
- Goal: Allow users to connect data streams from popular wearable devices (Fitbit, Apple Health, Google Fit) to automatically populate vital signs and activity data.
- Technical Challenges: Requires implementing OAuth2 flows for third-party platform authentication and using their respective APIs to fetch data. Data mapping and normalization across different platforms is also a challenge.
- Impact: Automates data entry for vital signs, providing a richer, more continuous dataset for personalized insights.
-
Personalized Health Insights and Trend Visualization:
- Goal: Utilize historical data (vitals, appointments, medication adherence patterns if tracked) to provide users with personalized, actionable insights and visual trends (e.g., charts of blood pressure over time).
- Technical Challenges: Requires robust data analysis capabilities and careful design to ensure insights are meaningful and not misleading. Visualization libraries (e.g., Chart.js on frontend, Matplotlib/Seaborn on backend for report generation) would be needed.
- Impact: Empowers users with a better understanding of their health journey and the impact of their behaviors or treatments.
Acknowledged Current Limitations:
Transparency about current limitations is important:
- Handwritten Prescription OCR Accuracy: While Gemini is advanced, accurately digitizing highly stylized, faint, or poorly written handwritten prescriptions remains a significant challenge. Estimated accuracy of ~85% means there's room for improvement; errors in critical fields like dosage are possible. Users must always verify against the original. Pre-processing and potential fine-tuning or prompt engineering for OCR could improve this.
- Language Support: Currently, the primary language for all processing and interaction is English. This limits accessibility for non-English speakers.
- No Dedicated Mobile Application: Access is via a web interface, which may not be as convenient or feature-rich as a native mobile app for on-the-go use. Responsive web design helps, but a native app is a distinct future possibility.
- Reliance on External APIs: Core functionalities depend on Google Gemini (OCR) and potentially Ollama (if not self-hosted robustly) or other LLM APIs. Availability, terms of service, and potential costs of these APIs are external factors. Network latency can also affect user experience.
- Depth of Medical Knowledge: The LLM's general knowledge and the RAG system's specific knowledge base define the system's expertise. Expanding and curating the RAG knowledge base with high-quality medical information is an ongoing process. It does not replace the nuanced knowledge of a trained medical professional.
- Context Window Limitations: LLMs have finite context windows. Very long chat histories or extremely large documents might require sophisticated summarization or chunking strategies to manage context effectively.
Call for Community Collaboration:
The project thrives on open collaboration. Contributions are welcome from individuals with diverse expertise:
- Medical Professionals (Doctors, Pharmacists, Nurses): Crucial for validating medical information accuracy, expanding the abbreviation lexicon, advising on drug interaction logic, and ensuring clinical relevance and safety. Help in curating RAG knowledge sources.
- AI/ML Engineers & Researchers: Improving OCR pre-processing, fine-tuning LLMs/embedding models, developing more advanced RAG strategies, exploring new AI-driven features.
- UI/UX Designers & Frontend Developers: Enhancing the web interface for better usability, accessibility (WCAG compliance), and overall user experience. Designing intuitive interfaces for new features.
- Backend Developers (Python/Flask): Optimizing performance, improving API design, implementing new features, strengthening security, and scaling the application.
- DevOps & Security Specialists: Improving CI/CD pipelines, infrastructure hardening, security testing, and ensuring best practices for deployment and data protection.
- Translators & Localization Experts: Assisting with UI translation and adapting content for different languages and cultural contexts.
Interested contributors should refer to the project's `CONTRIBUTING.md` file (if available) for guidelines on setting up the development environment, coding standards, and the process for submitting contributions (e.g., pull requests).
Conclusion and Valuable Resources
The Intelligence Assistance Chatbot Project represents a significant step towards leveraging advanced AI and web technologies to tackle tangible challenges in healthcare information accessibility. By empowering individuals with a clearer understanding of their medical data, particularly complex prescriptions, the project aims to foster better health management, improve medication adherence, and enhance patient-provider communication. The robust architecture, combining sophisticated NLP/OCR with a user-centric design, provides a resilient and extensible platform for continued innovation and meaningful impact.
The journey of this project is ongoing. We encourage you to delve into the codebase, experiment with its features, and consider contributing your expertise. Your feedback, insights, and collaborative efforts are invaluable in shaping a tool that can genuinely make a difference in how people interact with and understand their health information.
Useful Links for Technologies Used:
Medical Information & Standards Resources:
Broader AI & Healthcare Informatics Resources: